Development of Machine Learning algorithms which enable new and exciting applications is progressing at a breakneck pace, and given the long turnaround time of hardware development, the designers of dedicated hardware accelerators are struggling to keep up. FPGAs offer an interesting alternative to ASICs, enabling a much faster and more flexible environment for such HW-SW co-development, and with projects such as the
FPGA interchange format (now part of
CHIPS Alliance), Google and Antmicrohave been turning the FPGA ecosystem to be ever more open and software driven.
The open RISC-V ISA was built with Machine Learning in mind, with its configurable and adaptable nature, flexible vector extensions and a rich ecosystem of open source implementations which can serve as an excellent starting point for new R&D projects.
Given their wide-ranging interests in edge AI, both Google and Antmicro have embraced RISC-V as Founding members as far back as 2015. Among
many other open source tools and building blocks that Antmicro is creating, we have invested heavily into enabling HW/SW co-development of ML solutions using RISC-V in our open source simulation framework, Renode.
RISC-V is also excellent for FPGA-based ML development. It offers a multitude of FPGA-friendly softcore options—such as VexRiscv and specialized ML-oriented extensions called CFU—which you can experiment in cheap, easily accessible hardware andRenode, using
Verilator co-simulation capabilities.
In this note, we will describe the CFU and the
CFU playground ML experimentation project that Antmicro and Google have been collaborating on to push forward FPGA acceleration of AI, and how to get started quickly with your very own hardware-assisted ML pipeline.
About the CFU
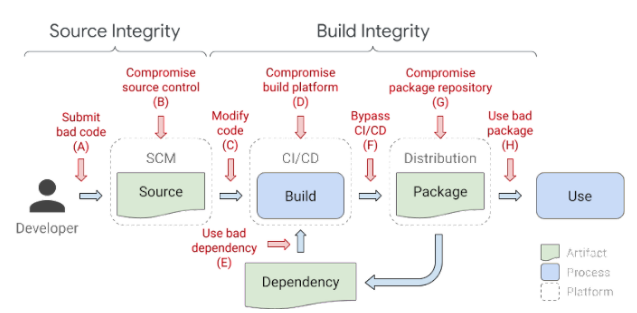
A “CFU”, or a “Custom Function Unit,” is an accelerator tightly coupled with the CPU. It adds a custom instruction to the ISA using a standardized format defined by the CFU working group of RISC-V International.
CFUs are easy to design, write, and experiment with given the reprogrammable nature of FPGAs. When working with a CFU, you are encouraged to identify blocks to be accelerated iteratively, measure your payload after each iteration and, above all, prepare custom CFUs for each payload (potentially using the capabilities of most FPGAs to be reprogrammed on the fly, or just holding several CFUs in store side by side, to be executed depending on the payload in question).
CFU execution is triggered by one of the standard instructions, with arguments passed via registers. The CPU can handle many different CFUs with various functions, their IDs are retrieved from the `funct7` and `funct3` operands of the decoded instruction. The only interaction between the CPU and the CFU is via registers and immediate values provided in the instruction itself—there is no direct memory access nor any interaction between different CFUs.
Figure 1
CFU Playground
Google’s CFU Playground provides an open source framework which offers a handy methodology for reasoning about ML acceleration and developing your own Custom Function Units using FPGAs and simulation. Various CFU examples and demos are available, and you can also add a project with your sources and modified TFLite Micro code (one of the results of our collaboration with the TF Lite Micro team). An overlay mechanism lets you override every part of code that you need.
A CFU may be written in Verilog or any language/framework that outputs Verilog. In the CFU Playground demos, CFUs are mostly written in nMigen, which allows you to write code in Python and then generates Verilog output. The Python-based flow simplifies development for software engineers who may not be familiar with writing Verilog code. Since it’s generated from Python, it is also very easy to upgrade in small steps in a structured way until you reach your expected acceleration targets.
Co-simulation in Renode
Renode has been supporting co-simulation of various buses since the 1.7.1 release, and support for CFU was also added recently. CFU support is done via the Renode Integration Layer plugin. It essentially consists of two parts: first, a C# class called `CFUVerilatedPeripheral,` which manages the Verilator simulation process, and second, an integration library written in C++. The integration library alongside the ‘verilated’ hardware code (i.e. HDL compiled into C++ via Verilator) are then built into a binary, which in turn is imported by the `CFUVerilatedPeripheral`. It is possible to install up to four different CFUs under one RISC-V CPU. Each of them will be executed based on the opcode received from the CPU.
Since the hardware is translated into C++ via Verilator, you can also enable tracing which dumps CFU waveforms into a file to later analyze.
How to ‘verilate’ your own CFU
Basic examples of verilated CFUs are available on
Antmicro’s GitHub. You can use this repository to ‘verilate’ your own custom CFU.
In the `main.cpp` of your verilated model, you need to include C++ headers from the Renode
Verilator Integration Library.
#include “src/renode_cfu.h”
#include “src/buses/cfu.h”
Next, you need to initialize the `RenodeAgent` and the model’s `top` instance along with the `eval()` function that will evaluate the model during simulation.
RenodeAgent *cfu;
Vcfu *top = new Vcfu;
void eval() {
top->eval();
}
Now add an `Init()` function that will initialize a bus along with its signals, and the `eval()` function. It should also initialize and return the `RenodeAgent` connected to a bus.
RenodeAgent *Init() {
Cfu* bus = new Cfu();
//=================================================
// Init CFU signals
//=================================================
bus->req_valid = &top->cmd_valid;
bus->req_ready = &top->cmd_ready;
bus->req_func_id = (uint16_t *)&top->cmd_payload_function_id;
bus->req_data0 = (uint32_t *)&top->cmd_payload_inputs_0;
bus->req_data1 = (uint32_t *)&top->cmd_payload_inputs_1;
bus->resp_valid = &top->rsp_valid;
bus->resp_ready = &top->rsp_ready;
bus->resp_ok = &top->rsp_payload_response_ok;
bus->resp_data = (uint32_t *)&top->rsp_payload_outputs_0;
bus->rst = &top->reset;
bus->clk = &top->clk;
//=================================================
// Init eval function
//=================================================
bus->evaluateModel = &eval;
//=================================================
// Init peripheral
//=================================================
cfu = new RenodeAgent(bus);
return cfu;
}
To compile your project, you must first export three environment variables:
- `RENODE_ROOT`: path to Renode source directory
- `VERILATOR_ROOT`:path to the directory where Verilator is located (this is not needed if Verilator is installed system-wide)
- `SRC_PATH`: path to the directory containing your `main.cpp`
With the variables above now set, go to `SRC_PATH` and build your CFU:
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=Release "$SRC_PATH"
make libVtop
If you need more details about creating your own ‘verilated’ peripheral, visit the chapter in
Renode documentation about co-simulation.
To attach a verilated CFU to a Renode platform, add `CFUVerilatedPeripheral` to your `RISC-V` CPU.
cpu: CPU.VexRiscv @ sysbus
cpuType: "rv32im"
cfu0: Verilated.CFUVerilatedPeripheral @ cpu 0
frequency: 100000000
As the last step, provide a path to a compiled verilated CFU. You can do it either in `.repl` platform as a CFU constructor or in `.resc` script.
cpu.cfu0 SimulationFilePath @libVtop.soTo see how it works without building your own project, run the built-in Renode demo script called
litex_vexriscv_verilated_cfu.resc in Renode’s monitor CLI:
(monitor) s @scripts/single-node/litex_vexriscv_verilated_cfu.rescCFU Playground Integration
CFU Playground makes use of a Continuous Integration mechanism to make sure new changes don’t break anything. Since the project is targeted mostly for real hardware, a simulator like Antmicro’s open source Renode framework is indispensable. A large number of varied tests are executed with every change in the mainline CFU Playground repository, building the CFUsoftware, and then running it in Renode with hardware co-simulation or with a software CFU reimplementation.
In the CI tests, Renode uses scripts which are generated for each specific build target. This makes it possible to generate the exact same scripts locally and run them in Renode to enable a step-by-step assessment of what is happening in the code.
What’s next?
CFU integration in Renode is already used in practice, among other places in the EU-funded project called
VEDLIoT, for which Antmicro also implemented the
Kenning framework. VEDLIoT will use Renode to develop and test a soft-SoC based system aimed to drive Tiny ML workloads.
Renode’s use in CFU Playground is yet another outcome of Antmicro’s long partnership with Google. Along with the testing and development work we did for the
TensorFlow Lite Micro team, this shows that Renode is and will continue to be a go-to framework for embedded ML developers.
By guest author Michael Gielda – Antmicro










 this can lead to substantial savings. For a quarter filling wavefunction on 48 qubits (24 orbitals) we would need 290 Gb and a qubit simulation would require 4.5 Petabytes.")