What is Server-side Apply?
One of the highest velocity OSS projects of all time, Kubernetes is a cornerstone of Google’s cloud strategy. By providing an abstraction layer between users’ workloads and the underlying infrastructure, Kubernetes enables managing containerized workloads and services across--and migration from--both public cloud competitors and on-premise data centers.In Config & Policy Automation (CPA) [1], in the Kubernetes Kernel team we aim to improve API expressiveness in Kubernetes so that more powerful controllers, tools, and UIs can be built using these APIs. The expressiveness and having better controllers, tools, and UIs are important to Google because they enable the ecosystem, and make it more sticky. It increases the ability to make more reliable systems that are simpler with better user experiences.
Bringing Server-side Apply to Kubernetes is one of the efforts led by Google to reduce fragmentation in clients, improve automation, and set Kubernetes up for ongoing success. Server-side Apply helps users and controllers manage their resources through declarative configurations. Clients can create and modify their objects declaratively by sending their fully specified intent. Server-side Apply replaces the client side apply feature implemented by “kubectl apply” with a Server-side implementation, permitting use by tools/clients other than kubectl (e.g. kpt). Server-side Apply is a new merging algorithm, as well as tracking of field ownership, running on the Kubernetes api-server. It enables new features like conflict detection, so the system knows when two actors are trying to edit the same field.
Server-side Apply Functionality
Since the Beta 2 release, subresources support has been added. Both client-go and Kubebuilder have added comprehensive support for Server-side Apply. This completes the Server-side Apply functionality required to make controller development practical.Support for subresources
Server-side Apply now fully supports subresources like status and scale. This is particularly important for controllers, which are often responsible for writing to subresources.Support in client-go
Previously, Server-side Apply could only be called from the client-go typed client using the Patch function, with PatchType set to ApplyPatchType. Now, Apply functions are included in the client to allow for a more direct and typesafe way of calling Server-side Apply. Each Apply function takes an "apply configuration" type as an argument, which is a structured representation of an Apply request.Using Server-side Apply in a controller
You can use the new support for Server-side Apply no matter how you implemented your controller. However, the new client-go support makes it easier to use Server-side Apply in controllers.
When authoring new controllers to use Server-side Apply, a good approach is to have the controller recreate the apply configuration for an object each time it reconciles that object. This ensures that the controller fully reconciles all the fields that it is responsible for. Controllers typically should unconditionally set all the fields they own by setting Force: true in the ApplyOptions. Controllers must also provide a FieldManager name that is unique to the reconciliation loop that apply is called from.
When upgrading existing controllers to use Server-side Apply the same approach often works well--migrate the controllers to recreate the apply configuration each time it reconciles any object. Unfortunately, the controller might have multiple code paths that update different parts of an object depending on various conditions. Migrating a controller like this to Server-side Apply can be risky because if the controller forgets to include any fields in an apply configuration that is included in a previous apply request, a field can be accidentally deleted. To ease this type of migration, client-go apply support provides a way to replace any controller reconciliation code that performs a "read/modify-in-place/update" (or patch) workflow with a "extract/modify-in-place/apply" workflow.
When authoring new controllers to use Server-side Apply, a good approach is to have the controller recreate the apply configuration for an object each time it reconciles that object. This ensures that the controller fully reconciles all the fields that it is responsible for. Controllers typically should unconditionally set all the fields they own by setting Force: true in the ApplyOptions. Controllers must also provide a FieldManager name that is unique to the reconciliation loop that apply is called from.
When upgrading existing controllers to use Server-side Apply the same approach often works well--migrate the controllers to recreate the apply configuration each time it reconciles any object. Unfortunately, the controller might have multiple code paths that update different parts of an object depending on various conditions. Migrating a controller like this to Server-side Apply can be risky because if the controller forgets to include any fields in an apply configuration that is included in a previous apply request, a field can be accidentally deleted. To ease this type of migration, client-go apply support provides a way to replace any controller reconciliation code that performs a "read/modify-in-place/update" (or patch) workflow with a "extract/modify-in-place/apply" workflow.
Using Server-side Apply in CI/CD
Server-side Apply makes it easier to ensure that clusters can be safely transitioned to the state desired by new code changes as done by CI/CD systems. While CI/CD systems are highly specific to each team, a few general guidelines can help make the most out of this new functionality.Once a code change results in new Kubernetes configurations (via whatever method the project uses to generate its Kubernetes configurations), the CI system can use server-side diff to present the developer and reviewer with details of what changes are being made as well as detecting any field ownership conflicts.
Developers can then iterate on field ownership conflicts until there are none left (or until the remaining conflicts are known and desired). Final approval can instruct the CD system to perform a Server-side Apply and either force conflicts to apply or instruct the system to block deployment on conflicts in case the cluster being deployed to has been modified in a way that creates new conflicts that the approver was previously unaware of.
Server-side Apply and CustomResourceDefinitions
It is strongly recommended that all Custom Resource Definitions (CRDs) have a schema. CRDs without a schema are treated as unstructured data by Server-side Apply. Keys are treated as fields in a struct and lists are assumed to be atomic. CRDs that specify a schema are able to specify additional annotations in the schema.Server-side Apply Example
A simple example of an object created by Server-side Apply (SSA) could look like Fig. 1. The object contains a single manager in metadata.managedFields. The manager consists of basic information about the managing entity itself, like operation type, API version, and the fields managed by it. SSA uses a more declarative approach, which tracks a user's field management, rather than a user's last applied state. This means that as a side effect of using SSA, information about which field manager manages each field in an object also becomes available.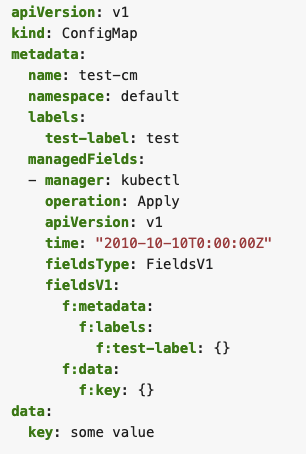
Fig 1. Server-side Apply Example
Server-side Apply use-cases in Google
Config Connector
Config Connector [3] leverages Server-side Apply to enable users to manage Google Cloud resources by both Config Connector and other configuration tools; e.g., gcloud, Cloud Console, or custom operators. Config Connector controllers use `managedFields` metadata to understand which fields are owned by Config Connector and which fields are managed outside the Kubernetes object [5]. Customers can have the flexibility of managing Google Cloud resources by both Config Connector and external tools; e.g., using a custom autoscaler for Bigtable clusters.Config Sync
Config Sync [2] lets cluster operators and platform administrators deploy consistent configurations and policies, by continuously reconciling the state of clusters with Kubernetes configs stored in Git repositories. Config Sync leverages SSA to apply the configs to the clusters, and then monitors and remediates configuration drift using SSA.KPT
KPT [4] is Git-native, schema-aware, extensible client-side tool for packaging, customizing, validating, and applying Kubernetes resources. KPT live apply leverages SSA to apply Kubernetes Resource Model (KRM) resources. It also uses SSA to preview the changes in KRM resources before applying them to the Kubernetes cluster.What's Next?
After Server-side Apply, the next focus for the API Expression working-group is around improving the expressiveness and size of the published Kubernetes API schema. To see the full list of items we are working on, please join our working group and refer to the work items document.How to get involved?
The working-group for apply is wg-api-expression. It is available on slack #wg-api-expression, through the mailing list.References
[1] CPA: Config & Policy Automation: https://cloud.google.com/anthos/config-management[2] Config Sync: https://cloud.google.com/anthos-config-management/docs/config-sync-overview
[3] Config Connector: https://cloud.google.com/config-connector/docs/overview
[4] KPT: https://opensource.google/projects/kpt
[5] Config Connector externally managed fields: https://cloud.google.com/config-connector/docs/concepts/managing-fields-externally