Reaching version 1.0 in just 2015, Rust is a relatively new language with a lot to offer. Developers eyeing the performance and safety guarantees that Rust provides, have to wonder if it's possible to just use Rust in place of what they've been using previously. What would happen if large companies tried to use it in their existing environment? How long would it take for developers to learn the language? Once they do, would they be productive?
In this post, we will analyze some data covering years of early adoption of Rust here at Google. At Google, we have been seeing increased Rust adoption, especially in our consumer applications and platforms. Pulling from the over 1,000 Google developers who have authored and committed Rust code as some part of their work in 2022, we’ll address some rumors head-on, both confirming some issues that could be improved and sharing some enlightening discoveries we have made along the way.
We’d like to particularly thank one of our key training vendors, Ferrous Systems, as we started our Rust adoption here at Google. We also want to highlight some new freely available self-service training materials called Comprehensive Rust 🦀 that we and the community have worked on over the last few quarters.
Rumor 1: Rust takes more than 6 months to learn – Debunked !
All survey participants are professional software developers (or a related field), employed at Google. While some of them had prior Rust experience (about 13%), most of them are coming from C/C++, Python, Java, Go, or Dart.
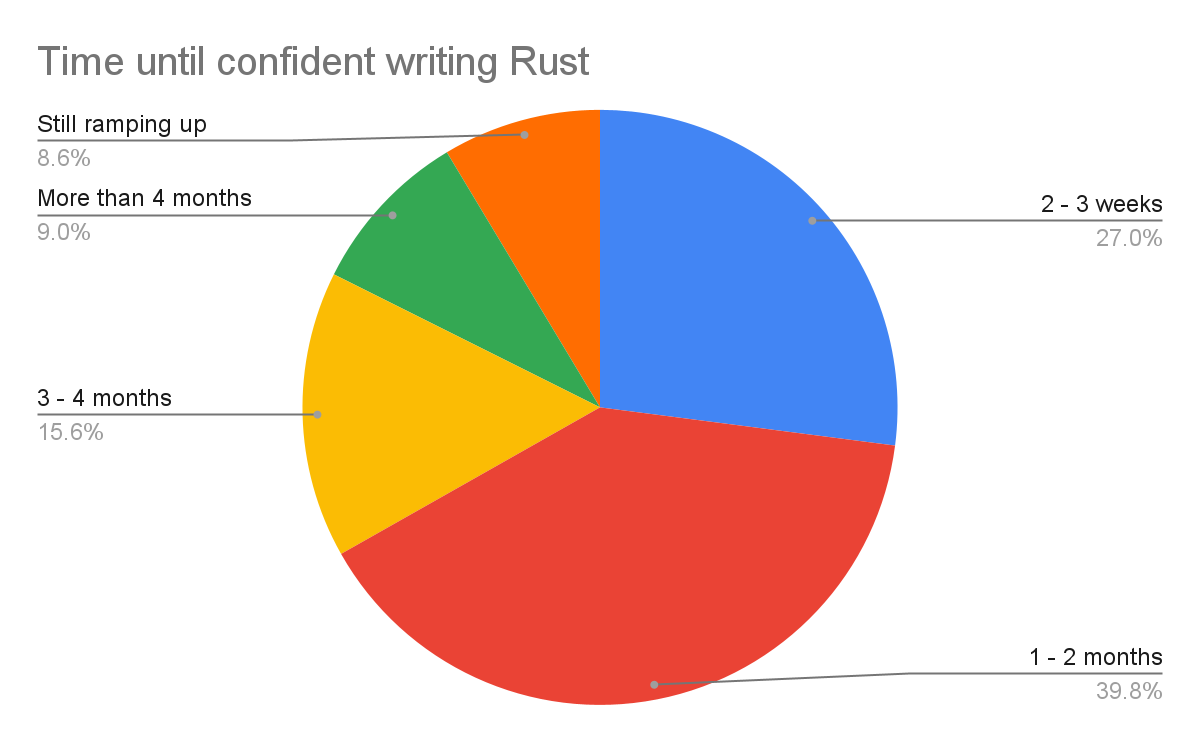
Based on our studies, more than 2/3 of respondents are confident in contributing to a Rust codebase within two months or less when learning Rust. Further, a third of respondents become as productive using Rust as other languages in two months or less. Within four months, that number increased to over 50%. Anecdotally, these ramp-up numbers are in line with the time we’ve seen for developers to adopt other languages, both inside and outside of Google.
Overall, we’ve seen no data to indicate that there is any productivity penalty for Rust relative to any other language these developers previously used at Google. This is supported by the students who take the Comprehensive Rust 🦀 class: the questions asked on the second and third day show that experienced software developers can become comfortable with Rust in a very short time.
 |
Rumor 2: The Rust compiler is not as fast as people would like – Confirmed !
Slow build speeds were by far the #1 reported challenge that developers have when using Rust, with only a little more than 40% of respondents finding the speed acceptable.
There is already a fantastic community-wide effort improving and tracking rustc performance. This is supported by both volunteers and several companies (including Google), and we’re delighted to see key developers working in this space but clearly continuing and potentially growing additional support here would be beneficial.
Rumor 3: Unsafe code and interop are always the biggest challenges – Debunked !
The top three challenging areas of Rust for current Google developers were:
Writing unsafe code and handling C/C++ interop were cited as something Google developers had encountered but were not top challenges. These three other areas are places where the Rust Language Design Team has been investing in flattening the learning curve overall as well as continued evolution, and our internal survey results strongly agree with these as areas of investment.
Rumor 4: Rust has amazing compiler error messages – Confirmed !
Rust is commonly regarded as having some of the most helpful error messages in the compiler space, and that held up in this survey as well. Only 9% of respondents are not satisfied with the quality of diagnostic and debugging information in Rust. Feedback from Comprehensive Rust 🦀 participants shows the same: people are amazed by the compiler messages. At first this is a surprise – people are used to ignoring large compiler errors, but after getting used to it, people love it.
The following are excerpts from an exercise some internal Googlers have been doing to practice Rust – solving Advent of Code 2021 in Rust.
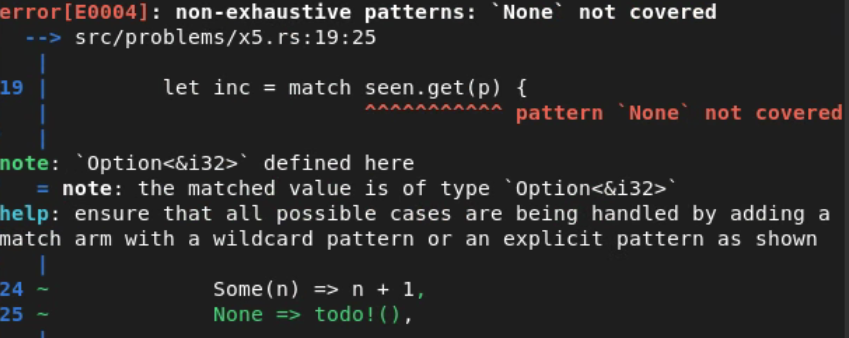
On Day 5 of the exercises, we need to perform a search for entries within a table. The error below not only detects that our pattern matching on the result was missing a case, but also makes a suggestion for a fix.
 |
On Day 11, we need to check for whether an element is within the bounds of a grid. The Rust warning below detects that we have a redundant comparison due to the fact that the types are unsigned, and suggests code that could be removed.
 |
Rumor 5: Rust code is high quality – Confirmed!
The respondents said that the quality of the Rust code is high — 77% of developers were satisfied with the quality of Rust code. In fact, when asked to compare whether they felt that Rust code was more correct than the code that they write in other languages, an overwhelming 85% of respondents are confident that their Rust code is correct.
And, it’s not just correct—it’s also easy to review. More than half of respondents say that Rust code is incredibly easy to review. As an engineering manager, that result is in many ways at least as interesting to me as the code authoring results, since code reviewing is at least as large a part of the role of a professional software engineer as authoring.
As both we at Google and others have noted, developer satisfaction and productivity are correlated with both code quality and how long it takes to get a code review. If Rust is not only better for writing quality code, but also better for getting that code landed, that’s a pretty compelling set of reasons beyond even performance and memory safety for companies to be evaluating and considering adopting it.
Looking forward
While over a thousand developers is a good sample of engineers, we look forward to further adoption and a future survey that includes many more use cases. In addition, while many of the developers surveyed joined teams without Rust experience, this population does have more excited early adopters than we would like from a broader survey. Stay tuned over the next year for another update!
By Lars Bergstrom, PhD – Android Platform Programming Languages and Kathy Brennan, PhD - Low-level Operating Systems Sr. User Experience Researcher