Since we open sourced the first version of Lyra on GitHub last year, we are delighted to see a vibrant community growing around it, with thousands of stars, hundreds of forks, and many comments and pull requests. There are people who fixed and formatted our code, built continuous integration for the project, and even added support for Web Assembly.
We are incredibly grateful for all these contributions, and we also heard the community's feedback, asking us to improve Lyra. Some examples of what developers wanted were to run Lyra on more platforms, develop applications in more languages; and for a model that computes faster with more bitrate options and lower latency, and better audio quality with fewer artifacts.
That's why we are now releasing Lyra V2, with a new architecture that enjoys a wider platform support, provides scalable bitrate capabilities, has better performance, and generates higher quality audio. With this release, we hope to continue to evolve with the community, and with its collective creativity, see new applications being developed and new directions emerging.
New Architecture
Lyra V2 is based on an end-to-end neural audio codec called SoundStream. The architecture has a residual vector quantizer (RVQ) sitting before and after the transmission channel, which quantizes the encoded information into a bitstream and reconstructs it on the decoder side.
.png)
Lyra V2's model is exported in TensorFlow Lite, TensorFlow's lightweight cross-platform solution for mobile and embedded devices, which supports various platforms and hardware accelerations. The code is tested on Android phones and Linux, with experimental Mac and Windows support. Operation on iOS and other embedded platforms is not currently supported, although we expect it is possible with additional effort. Moreover, this paradigm opens Lyra to any future platform supported by TensorFlow Lite.
Better Performance
With the new architecture, the delay is reduced from 100 ms with the previous version to 20 ms. In this regard, Lyra V2 is comparable to the most widely used audio codec Opus for WebRTC, which has a typical delay of 26.5 ms, 46.5 ms, and 66.5 ms.
Lyra V2 also encodes and decodes five times faster than the previous version. On a Pixel 6 Pro phone, Lyra V2 takes 0.57 ms to encode and decode a 20 ms audio frame, which is 35 times faster than real time. The reduced complexity means that more phones can run Lyra V2 in real time than V1, and that the overall battery consumption is lowered.
Higher Quality
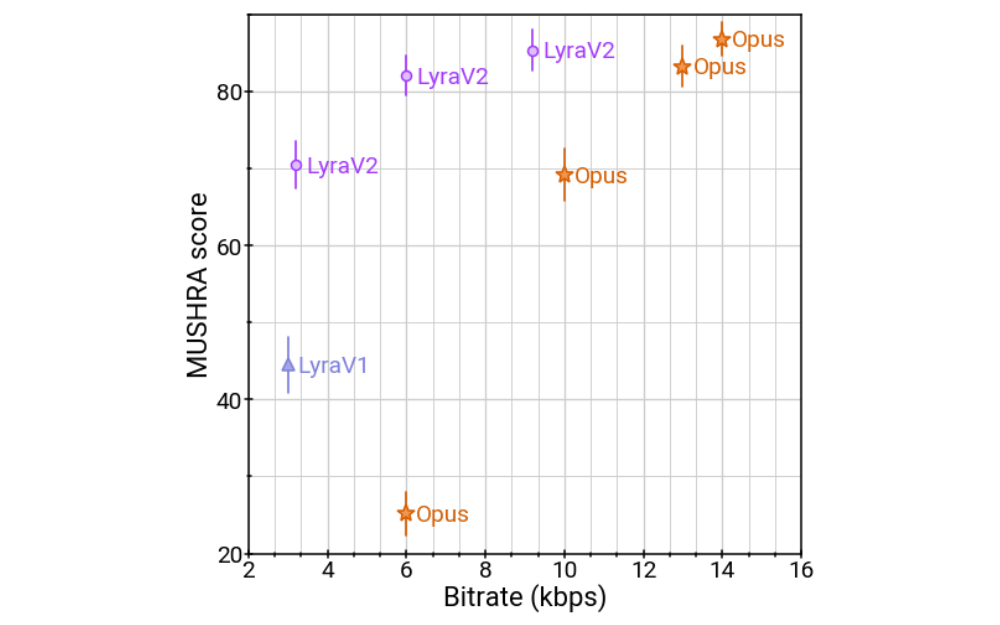
Driven by the advance of machine learning research over the years, the quality of the generated audio is also improved. Our listening tests show that the audio quality (measured in MUSHRA score, an indication of subjective quality) of Lyra V2 at 3.2 kbps, 6 kbps, and
9.2 kbps measures up to Opus at 10 kbps, 13 kbps, and 14 kbps respectively.
|
Sample 1 |
|
|---|---|
|
Original |
|
|
Opus@6kbps |
|
|
LyraV1 |
|
|
Opus@10kbps |
|
|
LyraV2@3.2kbps |
|
|
Opus@13k |
|
|
LyraV2@6kbps |
|
|
Opus@14kbps |
|
|
LyraV2@9.2kbps |
|
Sample 2 |
|
|---|---|
|
Original |
|
|
Opus@6kbps |
|
|
LyraV1 |
|
|
Opus@10kbps |
|
|
LyraV2@3.2kbps |
|
|
Opus@13k |
|
|
LyraV2@6kbps |
|
|
Opus@14kbps |
|
|
LyraV2@9.2kbps |
This makes Lyra V2 a competitive alternative to other state-of-the-art telephony codecs. While Lyra V1 already compares favorably to the Adaptive Multi-Rate (AMR-NB) codec, Lyra V2 further outperforms Enhanced Voice Services (EVS) and Adaptive Multi-Rate Wideband (AMR-WB), and is on par with Opus, all the while using only 50% - 60% of their bandwidth.

|
Sample 1 |
|
|---|---|
|
Original |
|
|
AMR-NB |
|
|
LyraV1 |
|
|
EVS |
|
|
AMR-WB |
|
|
Opus@13k |
|
|
LyraV2@6kbps |
|
Sample 2 |
|
|---|---|
|
Original |
|
|
AMR-NB |
|
|
LyraV1 |
|
|
EVS |
|
|
AMR-WB |
|
|
Opus@13k |
|
|
LyraV2@6kbps |
This means more devices can be connected in bandwidth-constrained environments, or that additional information can be sent over the network to reduce voice choppiness through forward error correction and packet loss concealment.
Open Source Release
Lyra V2 continues to provide what is already in Lyra V1 (the build tools, the testing frameworks, the C++ encoding and decoding API, the signal processing toolchain, and the example Android app). Developers who have experience with the Lyra V1 API will find that the V2 API looks familiar, but with a few changes. For example, now it's possible to change bitrates during encoding (more information is available in the release notes). In addition, the model definitions and weights are included as .tflite files. As with V1, this release is a beta version and the API and bitstream are expected to change. The code for running Lyra is open sourced under the Apache license. We can’t wait to see what innovative applications people will create with the new and improved Lyra!
By Hengchin Yeh - Chrome
Acknowledgements
The following people helped make the open source release possible: from Chrome: Alejandro Luebs, Michael Chinen, Andrew Storus, Tom Denton, Felicia Lim, Bastiaan Kleijn, Jan Skoglund, Yaowu Xu, Jamieson Brettle, Omer Osman, Matt Frost, Jim Bankoski; and from Google Research: Neil Zeghidour, Marco Tagliasacchi