

Diffusion models are state-of-the-art in generating photorealistic images from text. These models are hard to control through only text and generation parameters. To overcome this, the open source community developed ControlNet (GitHub), a neural network structure to control diffusion models by adding more conditions on top of the text prompts. These conditions include canny edge filters, segmentation maps, and pose keypoints. Thanks to the 🧨diffusers library, it is very easy to train, fine-tune or control diffusion models written in various frameworks, including JAX!
At Hugging Face, we were particularly excited to see the open source machine learning (ML) community leverage these tools to explore fun and creative diffusion models. We joined forces with Google Cloud to host a community sprint where participants explored the capabilities of controlling Stable Diffusion by building various open source applications with JAX and Diffusers, using Google Cloud TPU v4 accelerators. In this three week sprint, participants teamed up, came up with various project ideas, trained ControlNet models, and built applications based on them. The sprint resulted in 26 projects, accessible via a leaderboard here. These demos use Stable Diffusion (v1.5 checkpoint) initialized with ControlNet models. We worked with Google Cloud to provide access to TPU v4-8 hardware with 3TB storage, as well as NVIDIA A10G GPUs to speed up the inference in these applications.
Below, we showcase a few projects that stood out from the sprint, and that anyone can create a demo themselves. When picking projects to highlight, we considered several factors:
- How well-described are the models produced?
- Are the models, datasets, and other artifacts fully open sourced?
- Are the applications easy to use? Are they well described?
The projects were voted on by a panel of experts and the top ten projects on the leaderboard won prizes.
Control with SAM
One team used the state-of-the-art Segment Anything Model (SAM) output as an additional condition to control the generated images. SAM produces zero-shot segmentation maps with fine details, which helps extract semantic information from images for control. You can see an example below and try the demo here.
 |
Fusing MediaPipe and ControlNet
Another team used MediaPipe to extract hand landmarks to control Stable Diffusion. This application allows you to generate images based on your hand pose and prompt. You can also use a webcam to input an image. See an example below, and try it yourself here.
 |
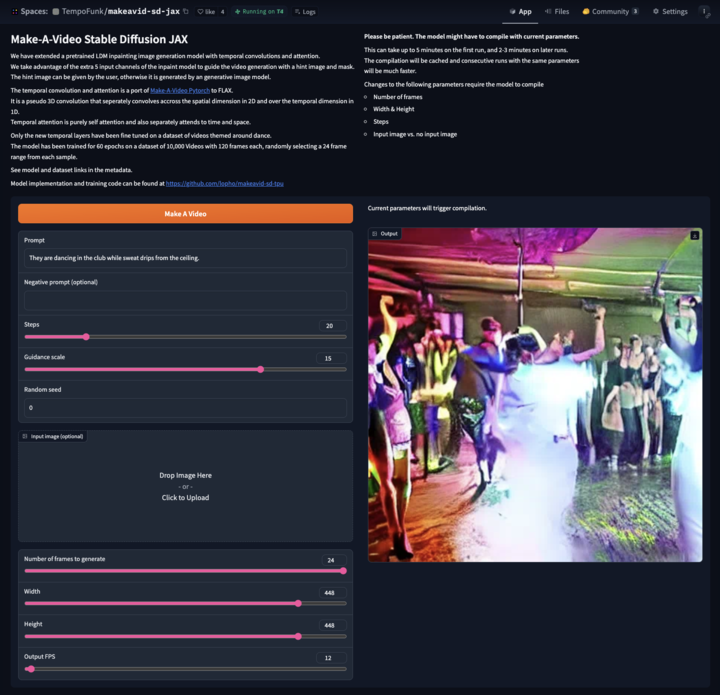
Make-a-Video
Top on the leaderboard is Make-a-Video, which generates video from a text prompt and a hint image. It is based on latent diffusion with temporal convolutions for video and attention. You can try the demo here.
 |
Bootstrapping interior designs
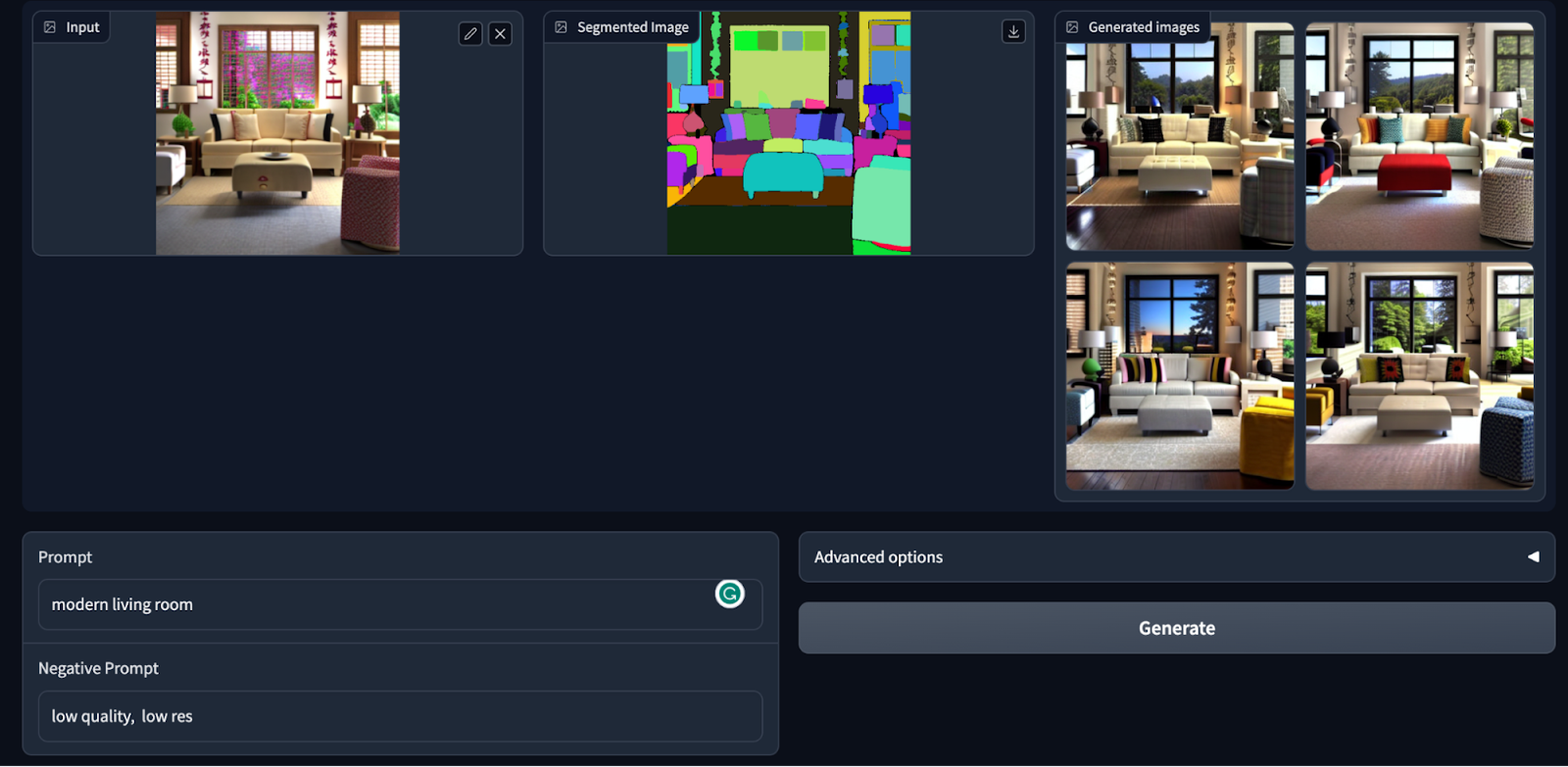
The project that won the sprint is ControlNet for interior design. The application can generate interior design based on a room image and prompt. It can also perform segmentation and generations, guided by image inpainting. See the application in inpainting mode below.
 |
In addition to the projects above, many applications were built to enhance images, like this application to colorize grayscale images. You can check out the leaderboard to try all the projects.
Learning more about diffusion models
To kick-off the sprint, we organized a three-day series of talks by leading scientists and engineers from Google, Hugging Face, and the open source diffusion community. We'd recommend that anyone interested in learning more about diffusion models and generative AI take a look at the recorded sessions below!
 |
| Tim Salimans (Google Research) speaking on Discrete Diffusion Models |
You can check out the sprint homepage to learn more.
Acknowledgements
We would like to thank Google Cloud for providing TPUs and storage to help make this great sprint happen, in particular Bertrand Rondepierre and Jonathan Caton for the hard work behind the scenes to get all of the Cloud TPUs allocated so participants had cutting-edge hardware to build on and an overall great experience. And also Andreas Steiner and Cristian Garcia for helping to answer questions in our Discord forum and for helping us make the training script example better. Their help is deeply appreciated.
By Merve Noyan and Sayak Paul – Hugging Face