

We are excited to announce the first PJRT plugin implementation in Intel Extension for TensorFlow, which seamlessly runs JAX models on Intel® GPU. The PJRT API simplified the integration, which allowed the Intel GPU plugin to be developed separately and quickly integrated into JAX. This same PJRT implementation also enables initial Intel GPU support for TensorFlow and PyTorch models with XLA acceleration.
 |
| Figure 1. Intel Data Center GPU Max Series |
With the shared vision that modular interfaces make integration easier and enable faster, independent development, Intel and Google collaborated in developing the TensorFlow PluggableDevice mechanism. This is the supported way to extend TensorFlow to new devices and allows hardware vendors to release separate plugin binaries. Intel has continued to work with Google to build modular interfaces for the XLA compiler and to develop the PJRT plugin to run JAX workloads on Intel GPUs.
JAX
JAX is an open source Python library designed for complex numerical computations on high-performance computing devices like GPUs and TPUs. It supports NumPy functions and provides automatic differentiation as well as a composable function transformation system to build and train neural networks.
JAX uses XLA as its compilation and execution backend to optimize and parallelize computations, particularly on AI hardware accelerators. When a JAX program is executed, the Python code is transformed into OpenXLA’s StableHLO operations, which are then passed to PJRT for compilation and execution. Underneath, the StableHLO operations are compiled into machine code by the XLA compiler, which can then be executed on the target hardware accelerator.
PJRT
PJRT (used in conjunction with OpenXLA’s StableHLO) provides a hardware- and framework-independent interface for compilers and runtimes (recent announcement). The PJRT interface supports the plugin from a new device backend. This interface provides a means for a straightforward integration of JAX into Intel's systems, and enables JAX workloads on Intel GPUs. Through PJRT integration with various AI frameworks, Intel’s GPU plugin can deliver hardware acceleration and oneAPI optimizations to a wider range of developers using Intel GPUs.
The PJRT API is a framework-independent API to allow upper level AI frameworks to compile and execute numeric computation represented in StableHLO on an AI hardware/accelerator. It has been integrated with popular AI frameworks including JAX, TensorFlow (via TF-XLA) and PyTorch (via PyTorch-XLA) which enables hardware vendors to provide one plugin for their new AI hardware and all these popular AI Frameworks will support it. It also provides low level primitives to enable efficient interaction with upper level AI frameworks including zero-copy buffer donation, light-weight dependency management, etc, which enables AI frameworks to best utilize hardware resources and achieve high-performance execution.
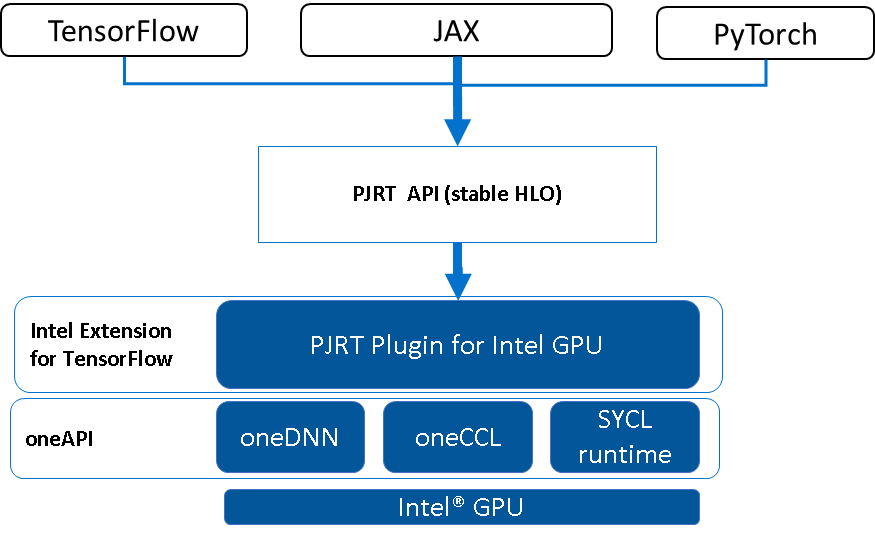 |
| Figure 2. PJRT simplifies the integration of oneAPI on Intel GPU into AI Frameworks |
PJRT Plugin for Intel GPU
The Intel GPU plugin implements the PJRT API by compiling StableHLO and dispatching the executable to Intel GPUs. The compilation is based on XLA implementation, adding target-specific passes for Intel GPUs and leveraging oneAPI performance libraries for acceleration. The device execution is supported using SYCL runtime. The Intel GPU Plugin also implements device registration, enumeration, and SPMD execution mode.
PJRT’s high-level runtime abstraction allows the plugin to develop its own low-level device management modules and use the advanced runtime features provided by the new device. For example, the Intel GPU plugin developed an out-of-order queue feature provided by SYCL runtime. Compared to fitting the plugin implementation to a low-level runtime interface, such as the stream executor C API used in PluggableDevice, implementing PJRT runtime interface is straightforward and efficient.
It’s simple to get started using the Intel GPU plugin to run a JAX program, including JAX-based frameworks like Flax and T5X. Just build the plugin (example documentation) then set the environment variable and dependent library paths. JAX automatically looks for the plugin library and loads it into the current process.
Below are example code snippets of running JAX on an Intel GPU.
$ export PJRT_NAMES_AND_LIBRARY_PATHS='xpu:Your_itex_library/libitex_xla_extension.so'
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:Your_Python_site-packages/jaxlib
$ python
import numpy as np
import jax
jax.local_devices() # PJRT Intel GPU plugin loaded
[IntelXpuDevice(id=0, process_index=0), IntelXpuDevice(id=1, process_index=0)]
x = np.random.rand(2,2).astype(np.float32)
y = np.random.rand(2,2).astype(np.float32)
z = jax.numpy.add(x, y) # Runs on Intel XPU |
Future Work
This PJRT plugin for Intel GPUs has also been integrated into TensorFlow to run XLA supported ops in TensorFlow models. However, XLA has a smaller op set than TensorFlow. For many TensorFlow models in production, some parts of the model graph are executed with PJRT (XLA compatible) while other parts are executed with the classic TensorFlow runtime using TensorFlow OpKernel. This mixed execution model requires PJRT and TensorFlow OpKernel to work seamlessly with each other. The TensorFlow team has introduced the NextPluggableDevice API to enable this.
When using NextPluggableDevice API, PJRT manages all critical hardware states (e.g. allocator, stream manager, driver, etc) and NextPluggableDevice API allows hardware vendors to build new TensorFlow OpKernels that can access those hardware states via PJRT. PJRT and NextPluggableDevice API enable interoperability between classic TensorFlow runtime and XLA, allowing the XLA subgraph to produce a PJRT buffer and feed to TensorFlow and vice versa.
As a next step, Intel will continue working with Google to adopt the NextPluggableDevice API to implement non-XLA ops on Intel GPUs supporting all TensorFlow models.
Written in collaboration with Jianhui Li, Zhoulong Jiang, and Yiqiang Li from Intel.
By Jieying Luo, Chuanhao Zhuge, and Xiao Yu – Google