

Overview
Container technology is an integral part of modern application ecosystems, making container security an increasingly important topic. Since containers are often used to run untrusted, potentially malicious code it is imperative to secure the host machine from the container.
A container's security depends on its security boundaries, such as user namespaces (which isolate security-related identifiers and attributes), seccomp rules (which restrict the syscalls available), and Linux Security Module configuration. Popular container management products like Docker and Kubernetes relax these and other security boundaries to increase usability, which means that users need additional container security tools to provide a much stronger isolation boundary between the container and the host.
The gVisor open source project, developed by Google, provides an OCI compatible container runtime called runsc. It is used in production at Google to run untrusted workloads securely. Runsc (run sandbox container) is compatible with Docker and Kubernetes and runs containers in a gVisor sandbox. gVisor sandbox has an application kernel, written in Golang, that implements a substantial portion of the Linux system call interface. All application syscalls are intercepted by the sandbox and handled in the user space kernel.
Although gVisor does not introduce large fixed overheads, sandboxing does add some performance overhead to certain workloads. gVisor has made several improvements recently that help containerized applications run faster inside the sandbox, including an improvement to the container root filesystem, which we will dive deeper into.
Costly Filesystem Access in gVisor
gVisor uses a trusted filesystem proxy process (“gofer”) to access the filesystem on behalf of the sandbox. The sandbox process is considered untrusted in gVisor’s security model. As a result, it is not given direct access to the container filesystem and its seccomp filters do not allow filesystem syscalls.
In gVisor, the container rootfs and bind mounts are configured to be served by a gofer.
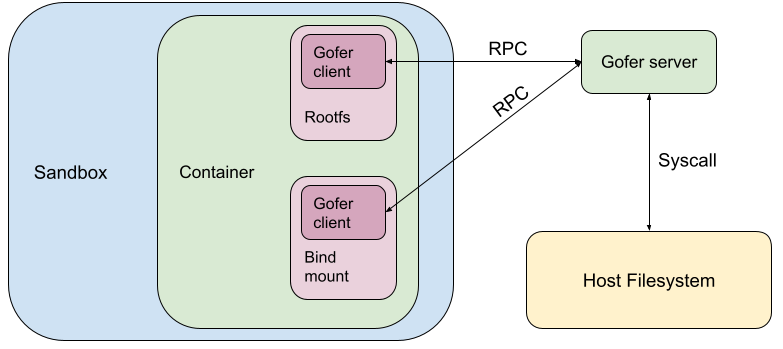 |
When the container needs to perform a filesystem operation, it makes an RPC to the gofer which makes host system calls and services the RPC. This is quite expensive due to:
- RPC cost: This is the cost of communicating with the gofer process, including process scheduling, message serialization and IPC system calls.
- To ameliorate this, gVisor recently developed a purpose-built protocol called LISAFS which is much more efficient than its predecessor.
- gVisor is also experimenting with giving the sandbox direct access to the container filesystem in a secure manner. This would essentially nullify RPC costs as it avoids the gofer being in the critical path of filesystem operations.
- Syscall cost: This is the cost of making the host syscall which actually accesses/modifies the container filesystem. Syscalls are expensive, because they perform context switches into the kernel and back into userspace.
Container Root Filesystem
In Docker and Kubernetes, the container’s root filesystem (rootfs) is based on the filesystem packaged with the image. The image’s filesystem is immutable. Any change a container makes to the rootfs is stored separately and is destroyed with the container. This way, the image’s filesystem can be shared efficiently with all containers running the same image. This is different from bind mounts, which allow containers to access the bound host filesystem tree. Changes to bind mounts are always propagated to the host and persist after the container exits.
Docker and Kubernetes both use the overlay filesystem by default to configure container rootfs. Overlayfs mounts are composed of one upper layer and multiple lower layers. The overlay filesystem presents a merged view of all these filesystem layers at its mount location and ensures that lower layers are read-only while all changes are held in the upper layer. The lower layer(s) constitute the “image layer” and the upper layer is the “container layer”. When the container is destroyed, the upper layer mount is destroyed as well, discarding the root filesystem changes the container may have made. Docker’s overlayfs driver documentation has a good explanation.
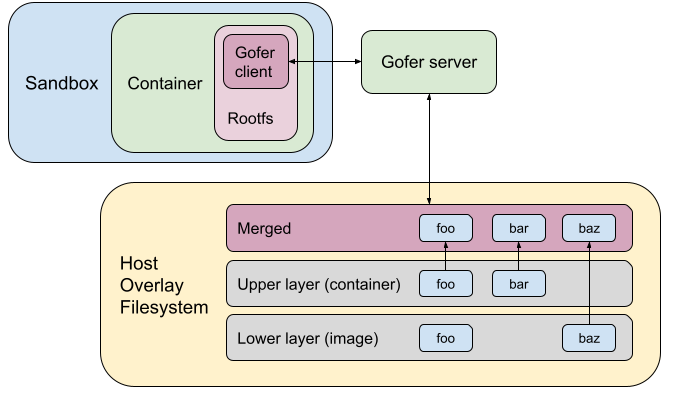
Rootfs Configuration Before
Let’s consider an example where the image has files foo and baz. The container overwrites foo and creates a new file bar. The diagram below shows how the root filesystem used to be configured in gVisor earlier. We used to go through the gofer and access/mutate the overlaid directory on the host. It also shows the state of the host overlay filesystem.
 |
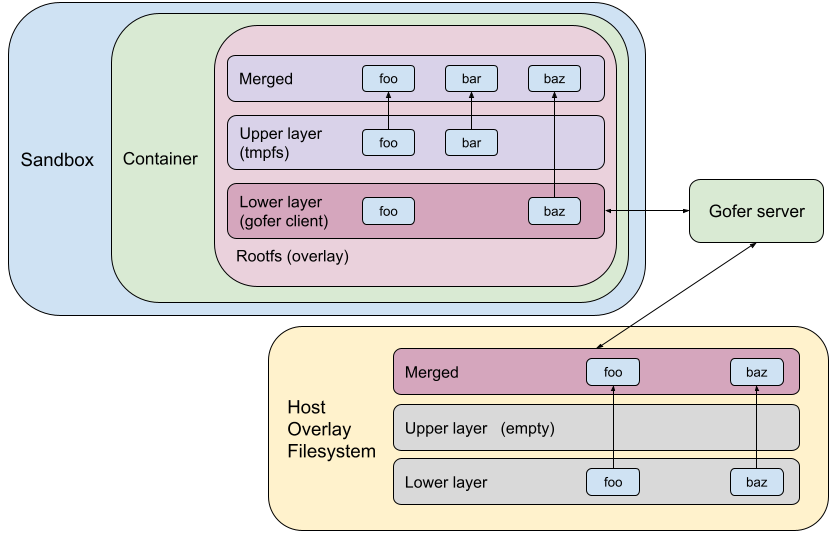
Opportunity! Sandbox Internal Overlay
Given that the upper layer is destroyed with the container and that it is expensive to access/mutate a host filesystem from the sandbox, why keep the upper layer on the host at all? Instead we can move the upper layer into the sandbox.
The idea is to overlay the rootfs using a sandbox-internal overlay mount. We can use a tmpfs upper (container) layer and a read-only lower layer served by the gofer client. Any changes to rootfs would be held in tmpfs (in-memory). Accessing/mutating the upper layer would not require any gofer RPCs or syscalls to the host. This really speeds up filesystem operations on the upper layer, which contains newly created or copied-up files and directories.
Using the same example as above, the following diagram shows what the rootfs configuration would look like using a sandbox-internal overlay.
 |
Host-Backed Overlay
The tmpfs mount by default will use the sandbox process’s memory to back all the file data in the mount. This can cause sandbox memory usage to blow up and exhaust the container’s memory limits, so it’s important to store all file data from tmpfs upper layer on disk. We need to have a tmpfs-backing “filestore” on the host filesystem. Using the example from above, this filestore on the host will store file data for foo and bar.
This would essentially flatten all regular files in tmpfs into one host file. The sandbox can mmap(2) the filestore into its address space. This allows it to access and mutate the filestore very efficiently, without incurring gofer RPCs or syscalls overheads.
Self-Backed Overlay
In Kubernetes, you can set local ephemeral storage limits. The upper layer of the rootfs overlay (writeable container layer) on the host contributes towards this limit. The kubelet enforces this limit by traversing the entire upper layer, stat(2)-ing all files and summing up their stat.st_blocks*block_size. If we move the upper layer into the sandbox, then the host upper layer is empty and the kubelet will not be able to enforce these limits.
To address this issue, we introduced “self-backed” overlays, which create the filestore in the host upper layer. This way, when the kubelet scans the host upper layer, the filestore will be detected and its stat.st_blocks should be representative of the total file usage in the sandbox-internal upper layer. It is also important to hide this filestore from the containerized application to avoid confusing it. We do so by creating a whiteout in the sandbox-internal upper layer, which blocks this file from appearing in the merged directory.
The following diagram shows what rootfs configuration would finally look like today in gVisor.
 |
Performance Gains
Let’s look at some filesystem-intensive workloads to see how rootfs overlay impacts performance. These benchmarks were run on a gLinux desktop with KVM platform.
Micro BenchmarkLinux Test Project provides a fsstress binary. This program performs a large number of filesystem operations concurrently, creating and modifying a large filesystem tree of all sorts of files. We ran this program on the container's root filesystem. The exact usage was:
You can use the -v flag (verbose mode) to see what filesystem operations are being performed.
The results were astounding! Rootfs overlay reduced the time to run this fsstress program from 262.79 seconds to 3.18 seconds! However, note that such microbenchmarks are not representative of real-world applications and we should not extrapolate these results to real-world performance.
Real-world BenchmarkBuild jobs are very filesystem intensive workloads. They read a lot of source files, compile and write out binaries and object files. Let’s consider building the abseil-cpp project with bazel. Bazel performs a lot of filesystem operations in rootfs; in bazel’s cache located at ~/.cache/bazel/.
This is representative of the real-world because many other applications also use the container root filesystem as scratch space due to the handy property that it disappears on container exit. To make this more realistic, the abseil-cpp repo was attached to the container using a bind mount, which does not have an overlay.
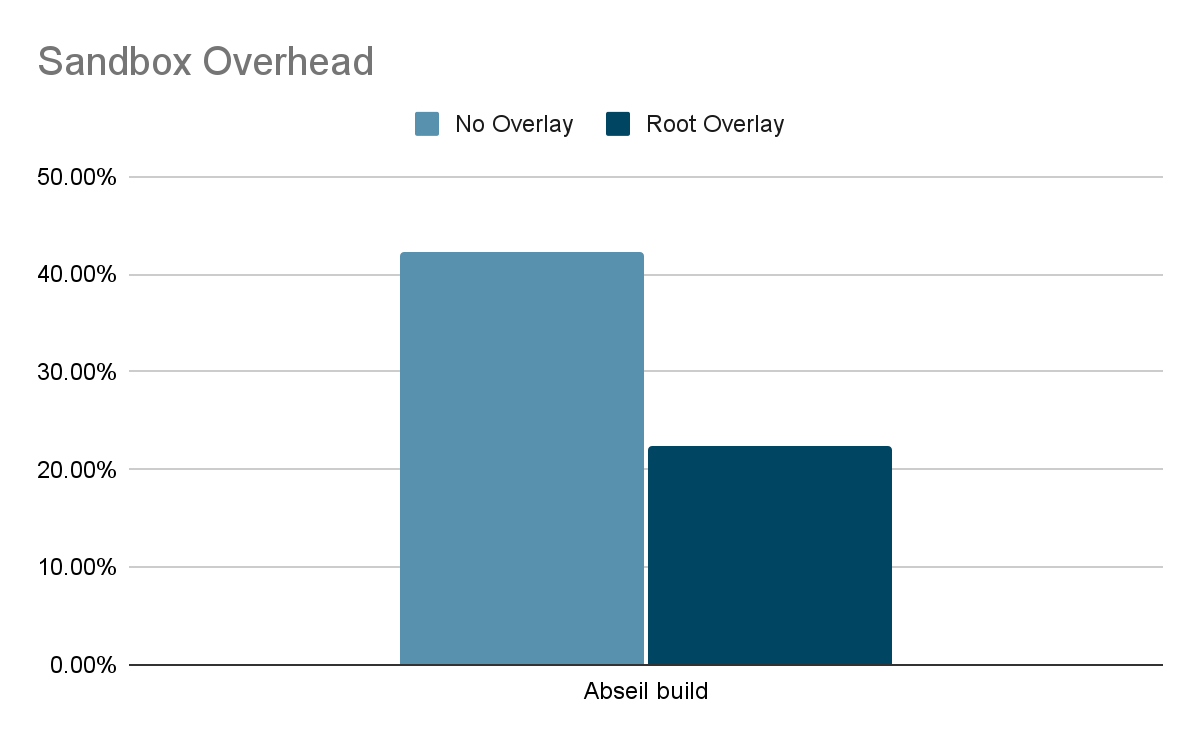
When measuring performance, we care about reducing the sandboxing overhead and bringing gVisor performance as close as possible to unsandboxed performance. Sandboxing overhead can be calculated using the formula overhead = (s-n)/n where ‘s’ is the amount of time taken to run a workload inside gVisor sandbox and ‘n’ is the time taken to run the same workload natively (unsandboxed). The following graph shows that rootfs overlay halved the sandboxing overhead for abseil build!
 |
Conclusion
Rootfs overlay in gVisor substantially improves performance for many filesystem-intensive workloads, so that developers no longer have to make large tradeoffs between performance and security. We recently made this optimization the default in runsc. This is part of our ongoing efforts to improve gVisor performance. You can learn more about gVisor at gvisor.dev. You can also use gVisor in GKE with GKE Sandbox. Happy sandboxing!
By Ayush Ranjan, Software Engineer, gVisor