

Over the years, we at Google have identified common requests from customers to optimize their Kubernetes clusters on Google Cloud. Today, we are releasing a set of open source tools to help customers with these tasks, including bin packing, load testing, and performance benchmarking. These tools are designed to help customers optimize their clusters for cost, performance, and scalability.
Those identified common requests from customers are around the following use cases:
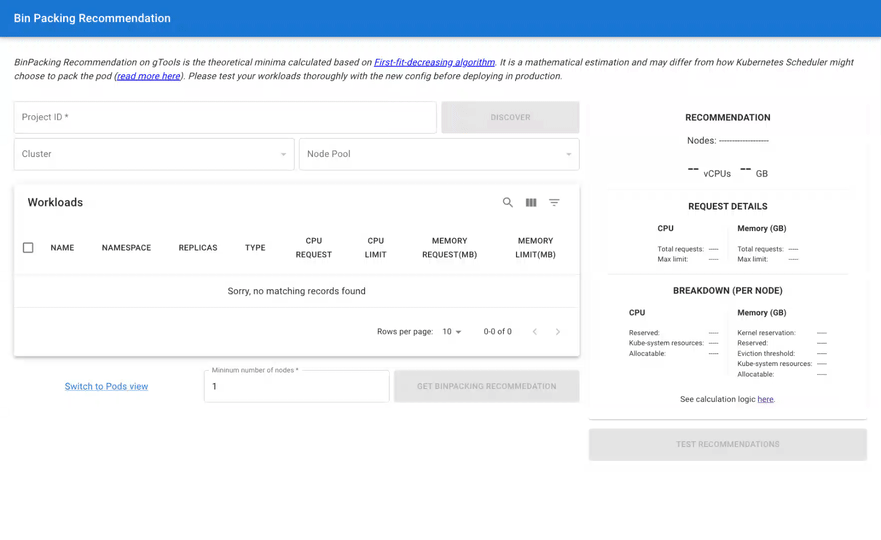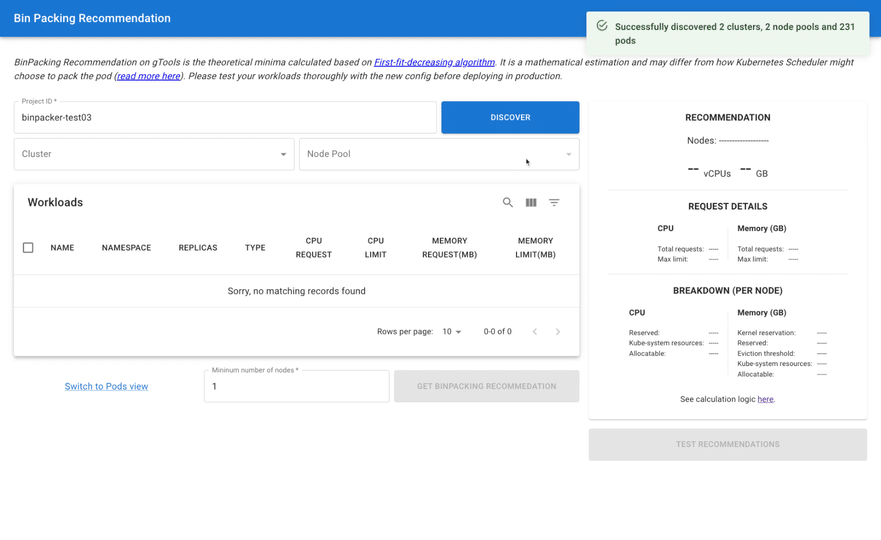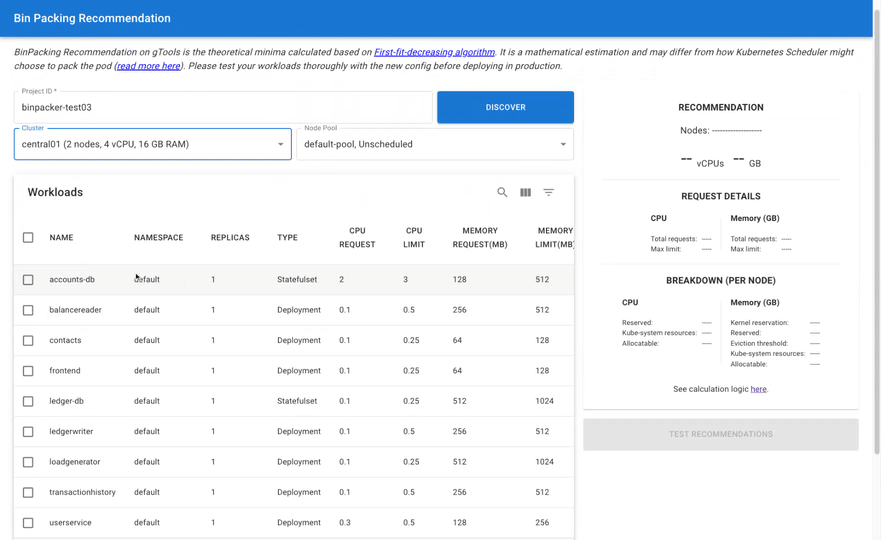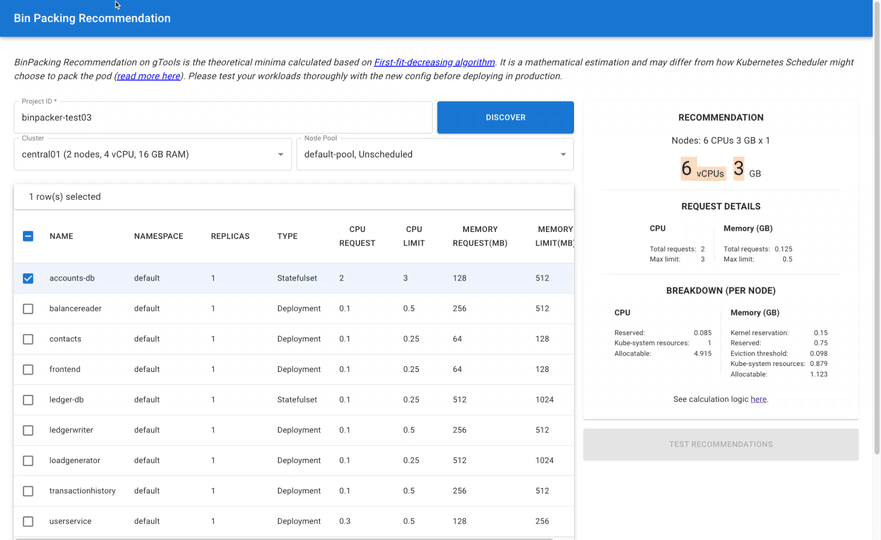
- Google Cloud customers ask whether Google Cloud has a bin packing recommendation feature or tool to optimize GKE Standard's nodes usage?
- How to easily run Aerospike, Cassandra, PgBench benchmark or other popular benchmarking tools on Google Cloud?
- How to load test our application running on Google Cloud? How many requests per second could my app handle given the current size of the existing Google Cloud infrastructure?
The underlying motivation is that customers want some evidence-based tooling in order to help them optimize their Google Cloud resources, optimize for cost, run benchmarks, identify performance bottlenecks, or even to start a performance discussion.
For such use cases mentioned above, we are open sourcing a set of tools for the public to self-service the installation of each application which comprises UI and Backend components deployable to their respective Google Cloud Project. We name the collection of these tools as sa-tools.
BinPacker
 |
Perfkit Benchmarker with UI
 |
What if you could install an easy-to-use version of Perfkit Benchmarker (PKB) with a click-and-select UI?
With this version, you could simply select the benchmark tool you want to use from a dropdown menu and provide a YAML configuration file. PKB would then automatically spin up a GKE Autopilot cluster with the configuration you have provided and run the benchmark. You could then view the performance metrics results in the UI.
This easy-to-use version of PKB would make it easier to run benchmarks and compare the performance of different systems, even if you don't have much technical experience. The installation guide can be found here.
Web Performance Testing
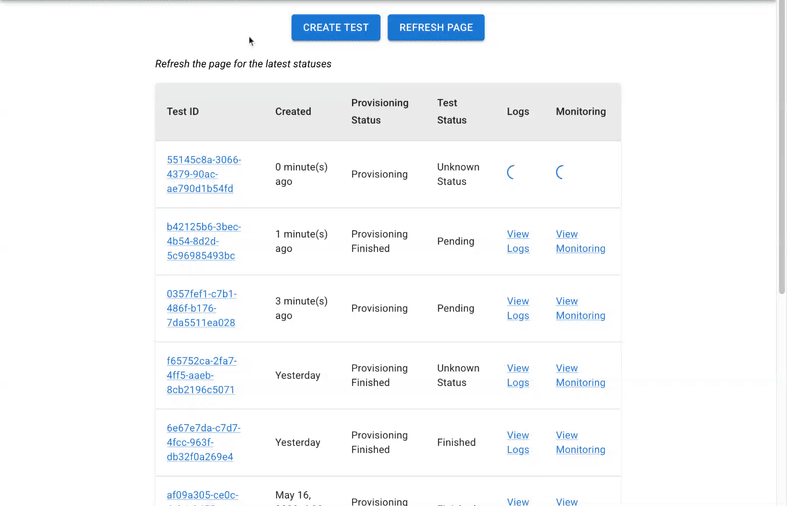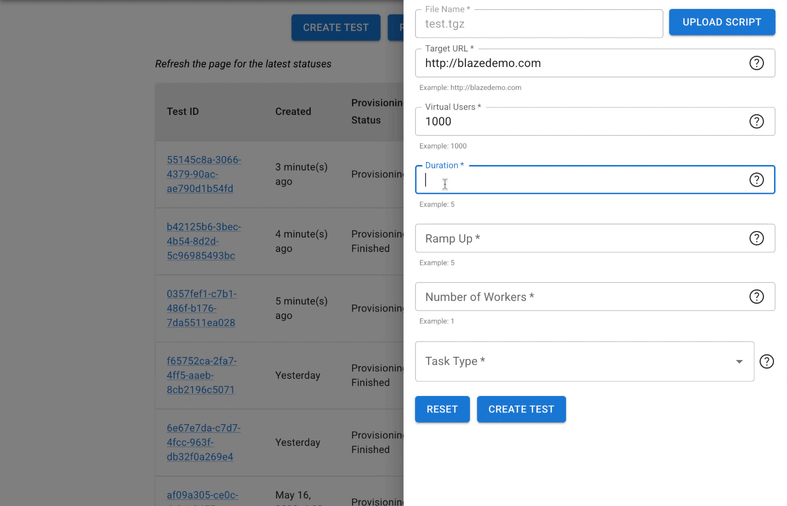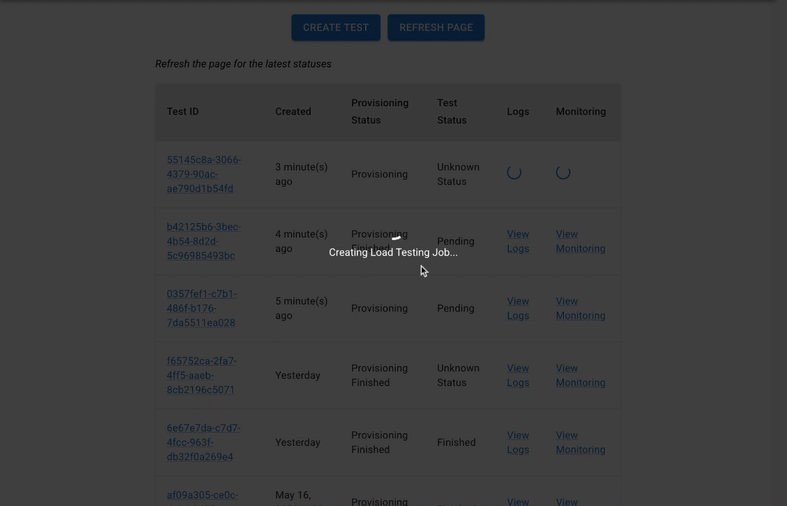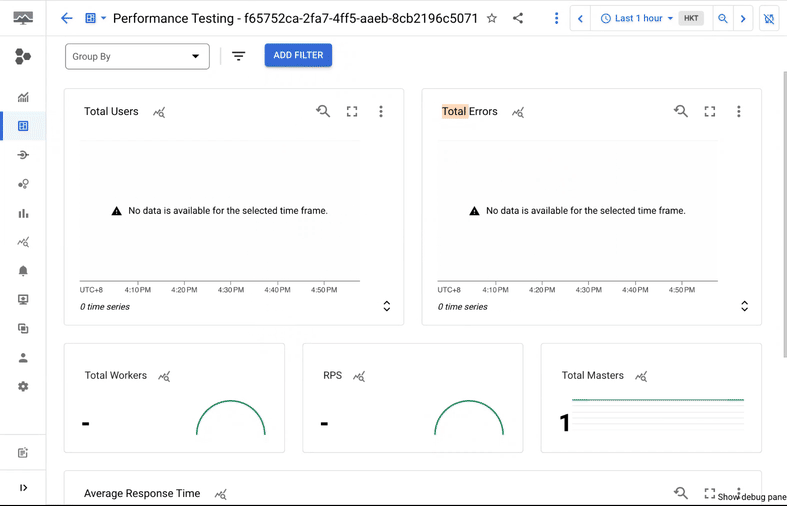 |
We built an open source UI wrapper on top of Locust, running inside your GCP Project. You can have a Locust farm instance run for a specific group of users in comparison to the generic Locust setup where everyone is able to access the Locust instance. The installation guide can be found here.
For more info on how to raise pull request or give feedback, please check the contributing page in the repository.
By Yudy Hendry, Anant Damle, Kozzy Hasebe, Jun Sheng, and Chuan Chen – Cloud Solutions Architects Team


